从纯自回归到纯扩散,再到混合架构与偏好对齐
这一波开源 musicgen / lyrics2song 系统,已经不再停留在 “能不能生成出声音” 这个层面,而是开始沿着几条相当清晰的技术路线分化:
- 一条是 大语言模型式的自回归路线,重点放在歌词对齐、段落结构和可控性上;
- 一条是 潜空间扩散路线,更强调速度、端到端生成和简洁的推理接口;
- 还有一条越来越主流的 混合路线,让 LM 负责规划,让 diffusion 或 DiT 负责高保真渲染;
- 再往后看,竞争焦点也已经从 “模型能不能生成” 逐渐转到了 “偏好对齐、风格控制、评测和可复现性怎么做”。
这篇文章不打算逐篇复述论文,而是想回答一个更实际的问题:
YuE、DiffRhythm、ACE-Step 1.5、LeVo 2 / SongGeneration 2、Muse,到底分别代表了 music generation 的哪条技术路线?
为了尽量避免信息漂移,本文主要参考这些系统在 2026 年 4 月 13 日之前公开的官方仓库、官方 README、项目页和论文摘要;其中少量 “路线归纳” 属于我基于公开材料做的总结判断,我会明确按 “我的理解” 来写。
# 先说结论
如果先压缩成一句话,我会这样概括:
| 系统 | 我对它的定位 | 核心路线 | 最突出的优化目标 |
|---|---|---|---|
| YuE | 把长程歌词对齐和完整歌曲结构做扎实的开源 AR 基座 | 自回归 LM | 长程结构、歌词一致性、ICL 风格迁移 |
| DiffRhythm | 用最直接的潜扩散方案把 “完整歌曲” 做成又快又简单 | 潜空间扩散 | 非自回归速度、端到端、低复杂度 |
| ACE-Step 1.5 | 让 LM 当规划器、让扩散当渲染器的强工程化混合体系 | 混合架构(LM + DiT /diffusion) | 速度、控制编辑、消费级部署 |
| LeVo 2 / SongGeneration 2 | 在混合架构上把 “偏好对齐” 和 “商用品质” 继续推高 | 混合架构 + 多阶段对齐 | 音乐性、歌词准确率、偏好多目标优化 |
| Muse | 把 “可复现长歌生成” 这件事系统化开源 | Qwen-based AR + MuCodec + 数据 / 评测全链路 | 可复现、细粒度风格控制、研究基础设施 |
如果再说得更直白一点:
- YuE 代表 “把 AR 歌曲模型做深做稳”;
- DiffRhythm 代表 “用 latent diffusion 替代慢速的 token-by-token 解码”;
- ACE-Step 1.5 代表 “规划和渲染分工” 的混合体系;
- LeVo 2 代表 “真正把质量继续往上拉的,不只是架构,还有后训练和偏好优化”;
- Muse 代表 “开源音乐生成不能只放权重,还要把数据、评测和风格控制接口一起放出来”。
# 1. YuE:最典型的长程自回归歌词到歌曲路线
YuE 的意义,不一定在于它是否绝对最强,而在于它把 长时长、带人声、歌词对齐的完整歌曲生成,以开源 AR foundation model 的方式做成了一个足够清晰的基线。
根据官方论文摘要和仓库说明,YuE 是一套 基于 LLaMA2 的长程音乐基础模型,目标明确指向 lyrics2song 。它公开强调的几个核心技术点包括:
track-decoupled next-token predictionstructural progressive conditioningmultitask, multiphase pre-training- 重新设计过的
in-context learning
从官方仓库还能直接看出,它的推理是 两阶段 的: stage1_model 负责更高层的歌曲内容生成, stage2_model 负责后续细化与重建;同时它支持单轨或双轨的音频 prompt,这对应的就是比较典型的 style transfer / continuation / ICL 工作流。
我的理解是,YuE 的核心哲学其实非常明确:
- 先承认歌曲生成本质上仍然是一个 长序列、强结构的 token 预测问题;
- 再通过更好的条件设计和更强的上下文建模,把 “歌词分段、旋律推进、伴奏协同” 这些问题尽量压进 AR 框架里解决。
这条路线的优点也很直观:
- 歌词和段落结构通常更容易 “讲清楚”;
- 文字条件、音频条件、双轨提示都比较自然;
- 风格迁移、续写、分段生成这类能力,和 LM 的条件建模天然兼容。
但它的代价同样明显:
- 推理慢;
- 长序列带来的显存压力大;
- 结构组织虽然强,但在声学细节和采样效率上天然不占便宜。
所以在这一波系统里,YuE 更像是一个 “AR 基准派”:它证明了开源模型完全可以把完整歌曲做出来,而且在歌词对齐和长程组织上依然有很强的竞争力。
# 2. DiffRhythm:把完整歌曲问题改写成潜空间扩散
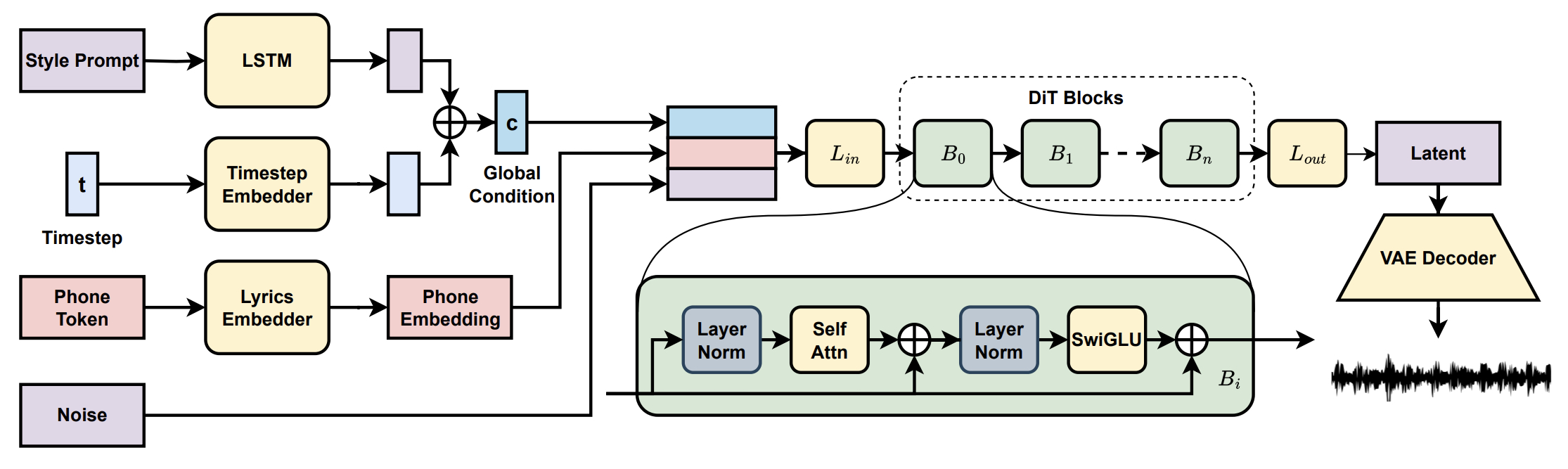
如果说 YuE 代表的是 “把 AR 做好”,那 DiffRhythm 代表的就是另一种思路:
既然自回归太慢,那就不要再按 token 一个一个往外吐,直接上 latent diffusion。
官方论文摘要和 README 对它的定位写得很直接:它是第一个能够做 full-length song generation 的开源 latent diffusion 歌曲系统,而且重点强调三件事:
- 生成 完整歌曲,时长可以到
4m45s - 推理只需要 lyrics + style prompt
- 整体结构是 non-autoregressive,因此速度很快
它最有代表性的表述反而不是 “结构有多复杂”,而是:
simple and elegant
换句话说,就是:
- 不依赖特别繁琐的数据管线;
- 模型结构尽量直接;
- 推理接口尽量简单;
- 用潜空间扩散把完整歌曲一次性生成出来。
这条路线的价值很大,因为它真正回答了一个工程问题:
歌曲生成能不能像图像生成那样,进入 “高吞吐、低交互成本、接口相对统一” 的阶段?
DiffRhythm 给出的答案是:可以,至少这个方向是可行的。
和 YuE 这种 AR 路线相比,DiffRhythm 的特点很鲜明:
- 速度更快
- 推理形式更直接
- 对最终音频的整体渲染更像一次性采样
但扩散路线的老问题也会随之出现:
- 长程结构控制没有 AR 那么 “离散、显式”;
- 歌词对齐和段落一致性往往需要更小心的设计;
- 如果没有更强的规划器,模型在 “整首歌的组织力” 上容易输给 LM 路线。
所以在技术谱系里,DiffRhythm 很像一个关键拐点:
它不是沿着 YuE 的路线继续卷参数,而是直接切换建模范式,告诉大家完整歌曲生成并不一定要坚持纯 AR。
# 3. ACE-Step 1.5:规划交给 LM,渲染交给 DiT
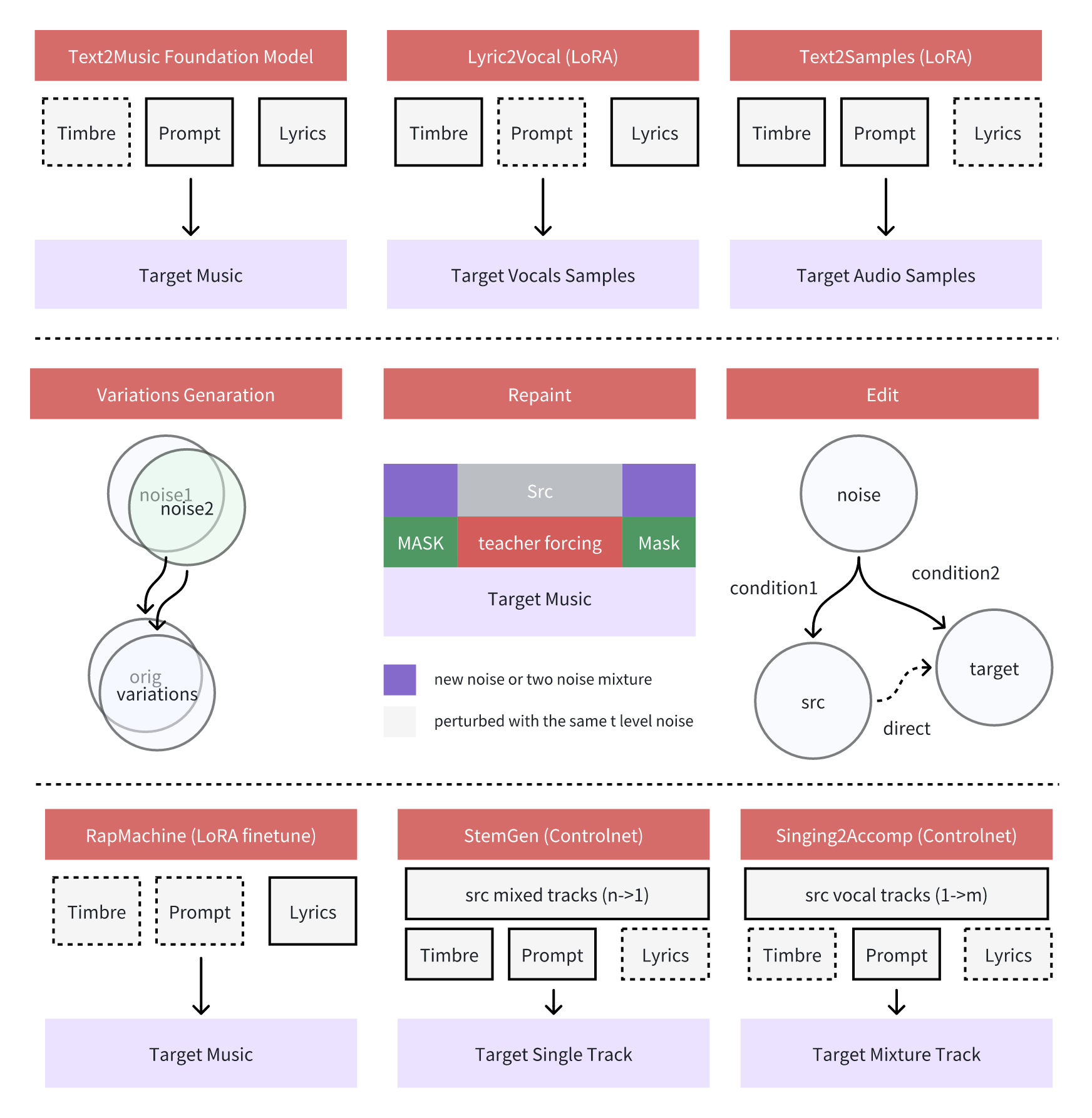
ACE-Step 初版就在做一件很明确的事:桥接 AR 和 diffusion 的优缺点。官方技术报告对问题的表述也相当清楚:
- LLM 路线歌词对齐强,但速度慢,而且容易出现结构伪影;
- 扩散路线速度快,但长程一致性偏弱。
它给出的答案包括:
- 用
DCAE压缩音频表示 - 用轻量
linear transformer/ LM 处理更高层的组织 - 用扩散式生成器保证高保真音频重建
- 用
MERT和m-hubert做语义对齐训练
到了 ACE-Step 1.5,这条思路进一步成熟。根据 2026 年 1 月 31 日公开的 v1.5 技术报告摘要,ACE-Step 1.5 的核心已经变成一个更明确的 hybrid planner-renderer architecture:
- LM 作为 omni-capable planner
- 把用户查询扩展成更完整的 song blueprint
- 通过
Chain-of-Thought生成 metadata、lyrics、captions 等中间结构 - 再去引导
Diffusion Transformer (DiT)完成音频生成
这其实是当前 musicgen 里非常值得重视的一种范式:
LM 负责 “想清楚”,扩散负责 “做漂亮”。
也就是说,ACE-Step 1.5 不再把 LM 直接当成最终声码器,而是把它放回更像 作曲规划器 / 条件展开器 / 结构编排器 的位置。这一步很关键,因为它让系统同时拿到了:
- LM 的结构组织能力
- Diffusion / DiT 的高保真渲染能力
- 更快的非自回归推理速度
官方材料里,ACE-Step 1.5 还特别强调了这些工程属性:
- 全曲生成速度极快
- 低显存可本地部署
- 支持 LoRA 个性化
- 支持 cover、repainting、vocal-to-BGM、lyric editing 等编辑能力
所以我会把 ACE-Step 1.5 看成目前最典型的 “音乐版 planner + renderer 分层系统”。它已经不再把 “模型主体” 理解成单一解码器,而是把它视为一个由规划、条件展开、渲染和编辑组成的整体工作流。
# 4. LeVo 2 / SongGeneration 2:混合架构之外,更关键的是多阶段偏好对齐
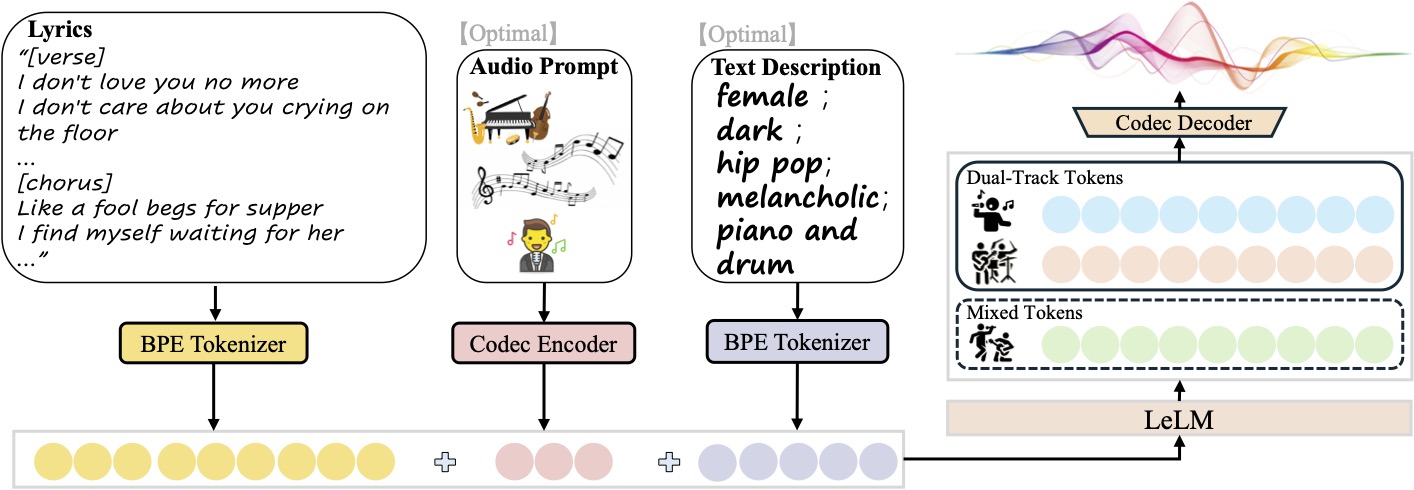
这里先把名字讲清楚。
你提到的 LeVo ,在目前公开代码里已经演化成 LeVo 2 / SongGeneration 2。截至 2026 年 3 月 1 日,官方 README 的最新说法是:他们开源的是 SongGeneration-v2-large ,并把它定义为追求 commercial-grade generation 的开源音乐基础模型。
这条路线最值得看的地方,不只是 “混合架构” 本身,而是它把 架构设计 和 后训练对齐 两边都搭成了完整体系。
在模型结构上,官方 README 给出的分工非常明确:
- Hybrid LLM-Diffusion Architecture
- LeLM 作为 “Composer Brain”
- Diffusion 作为 “Hi-Fi Renderer”
- 再加一个 Hierarchical Language Model
而这个 hierarchical LM 又继续区分了两种 token:
Mixed TokensDual-Track Tokens
这和 LeVo 旧版论文里描述的路线是一致的:一部分 token 抓高层语义和整体结构,另一部分 token 并行建模人声与伴奏的精细关系。它本质上是在回答一个很核心的问题:
歌曲不是普通的单流音频,它天然就有 “混音整体” 和 “分轨细节” 两层表示,能不能把这两层都建模?
LeVo / SongGeneration 给出的答案是:可以,而且应该并行建模。
但更重要的是它的训练策略。SongGeneration 2 在官方 README 里明确把提升重点放在一个三阶段后训练流程上:
SFTLarge-scale Offline DPOSemi-online DPO
这说明它并不满足于 “把模型训出来”,而是把竞争重点放在:
- 怎么减少 lyrical hallucination
- 怎么提升 musicality
- 怎么在多维偏好上做统一优化
官方还特别强调了:
PER = 8.55- 多语言歌词支持
- 更接近商业系统的整体质量
我的理解是,LeVo 2 / SongGeneration 2 代表的是一种更成熟的工业化路线:
- 架构上承认混合模型更合理;
- 表示层上承认 mixed /dual-track 需要同时建模;
- 训练上承认真正的差距,很多时候来自 偏好优化和后训练数据构造。
也就是说,LeVo 的关键贡献不只是 “模型怎么搭”,而是:
高质量歌曲生成最后拼的,往往很大程度上就是 alignment pipeline。
# 5. Muse:把可复现、风格控制和评测全链路一起开源
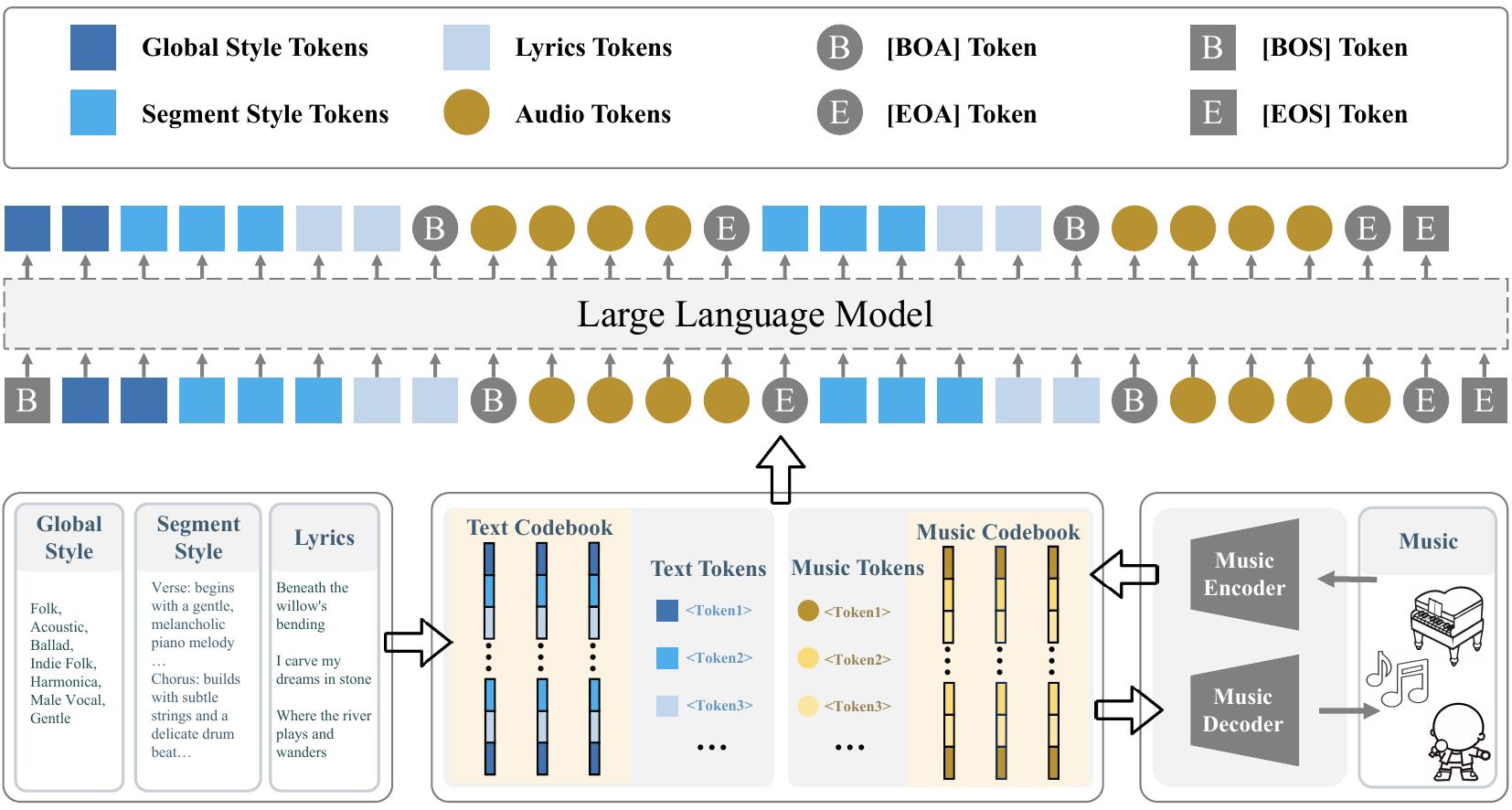
Muse 是这几套系统里,我觉得最偏 “研究基础设施导向” 的一个。
它关注的问题不是 “我要不要比谁快 20%”,而更像是:
既然很多商业长歌系统很强,但学术界很难复现,那能不能把训练数据、训练流程、评测流程和模型本身一起开放出来?
官方 README 和论文摘要给出的信息很清楚:
- Muse 面向 long-form song generation
- 支持 fine-grained style conditioning
- 放出了 116k fully licensed synthetic songs
- 使用 Qwen-based language model
- 用
MuCodec把音频离散成 audio tokens - 训练上采用 single-stage supervised finetuning
- 不依赖 task-specific loss、auxiliary objective 或额外复杂结构
这条路线很有意思,因为它没有像 ACE-Step 或 LeVo 那样把 “混合架构” 作为最大卖点,而更像是在说:
先把一条足够干净、足够可复现、足够可控的 AR song generation pipeline 搭完整。
从技术气质上看,Muse 更接近:
- 基于强文本 LM 的统一序列建模
- 在输入里显式放入全局风格标签、分段风格描述和歌词
- 用 segment-level 条件实现更细粒度的控制
因此它的贡献重点更偏向三件事:
- 研究可复现
- 风格条件设计
- 公开评测与数据流程
所以如果说 YuE 是 “AR 路线的强生成器”,那 Muse 更像 “AR 路线的可复现研究平台”。两者并不对立,只是关注点不同:
- YuE 更强调生成能力的上限;
- Muse 更强调整个研究闭环是否对社区开放。
# 五条路线真正的分野在哪里
把这几套系统放在一起看,我觉得它们真正的分野,可以归结为四个问题。
# 1. 谁来负责长程结构?
- YuE / Muse 更偏向让自回归 LM 直接承担长程结构组织;
- DiffRhythm 让扩散模型直接处理整首歌的生成;
- ACE-Step / LeVo 则更倾向于把结构规划单独抽出来,让 LM 先生成 blueprint,再由扩散或 DiT 去渲染。
这也是为什么我会觉得混合路线会越来越主流:
LM 确实更适合 “组织”,扩散也确实更适合 “渲染”。
# 2. 谁来保证人声与伴奏的协同?
- YuE 通过更强的条件建模和分轨 / 双轨 ICL 去做;
- DiffRhythm 通过端到端 latent diffusion 直接联合建模;
- LeVo 把这个问题显式拆成
mixed tokens + dual-track tokens; - ACE-Step 则更像是在 blueprint 到 audio 的多阶段过程中处理它。
这里 LeVo 的想法尤其有代表性:
歌曲不是单流 audio,而是天然带有多层表示。
# 3. 谁最重视 “偏好对齐”?
- YuE 的重点更偏 foundation model 的建模设计;
- DiffRhythm 初代更偏建模范式切换;
- ACE-Step 已经明显把编辑和控制能力纳入统一框架;
- LeVo 2 / SongGeneration 2 则把
DPO + 多阶段 alignment放到了系统核心; - Muse 更像是从数据和评测基础设施入手,去保证比较公平、可复现。
换句话说,LeVo 代表的是一种 “后训练时代” 的思路:
模型本体只是上半场,alignment 才是下半场。
# 4. 谁最像真正能落地的产品底座?
从目前公开信息看:
- DiffRhythm 最像 “轻量、快、上手简单” 的扩散产品底座;
- ACE-Step 1.5 最像 “功能全面、可编辑、消费级部署友好” 的创作工作流底座;
- LeVo 2 最像 “朝商用品质逼近” 的系统化方案;
- YuE 更像强生成能力的开源里程碑;
- Muse 更像可复现研究平台。
它们并不是同一个维度上的 “谁替代谁”,而是分别站在:
- 研究基线
- 范式切换
- 混合架构
- 偏好优化
- 开源复现
这五个不同重心上。
# 我自己的判断
如果只看未来一两代系统的主流方向,我的判断是:
纯 AR 不会消失,但 “LM 负责规划,扩散负责渲染” 的混合路线,大概率会成为开源 full-song generation 的主轴。
原因并不复杂:
- 纯 AR 在歌词对齐和结构控制上依然强;
- 纯扩散在速度和高保真渲染上天然有优势;
- 混合系统最有机会同时拿到两边的好处。
而在混合系统内部,接下来的竞争点,大概率会继续往这几个方向收敛:
- 更细的分轨 / 中间表示设计
- 更强的 segment-level planning
- 更系统的 preference alignment
- 更低成本的本地部署和 LoRA 个性化
- 更公开、可复现的数据与评测基准
也正因为如此,把这几篇工作放在一起看才有意思:
- YuE 告诉我们 AR 歌曲 foundation model 可以做到什么;
- DiffRhythm 告诉我们 full-song generation 不一定非得坚持 AR;
- ACE-Step 1.5 告诉我们规划和渲染分层是一条很强的工程路线;
- LeVo 2 告诉我们 alignment pipeline 可能比单纯换 backbone 更重要;
- Muse 告诉我们,一个健康的研究生态还需要数据、评测和复现闭环。
这五条路线,基本构成了当前开源 musicgen 最值得关注的一张技术地图。
# 补充:从 UniAudio 到 HeartMuLa /heartlib,这条路径到底在做什么
这一节我想单独展开一下 https://github.com/HeartMuLa/heartlib ,因为它背后的技术路径其实非常有代表性:
它不是凭空冒出来的一套音乐系统,而是可以相当清楚地追溯到 UniAudio 那条 “统一离散 token 建模” 路线。
如果用一句话概括这条演化链,我会这样说:
UniAudio 先提出 “把不同音频任务都变成统一 token 序列,让一个模型去做”;HeartMuLa 则把这个思想从 “通用音频框架” 收缩并强化成 “面向音乐的专用 foundation model + 专用 codec + 专用工具链”。
下面按逻辑一层一层展开。
# 1. 起点为什么是 UniAudio
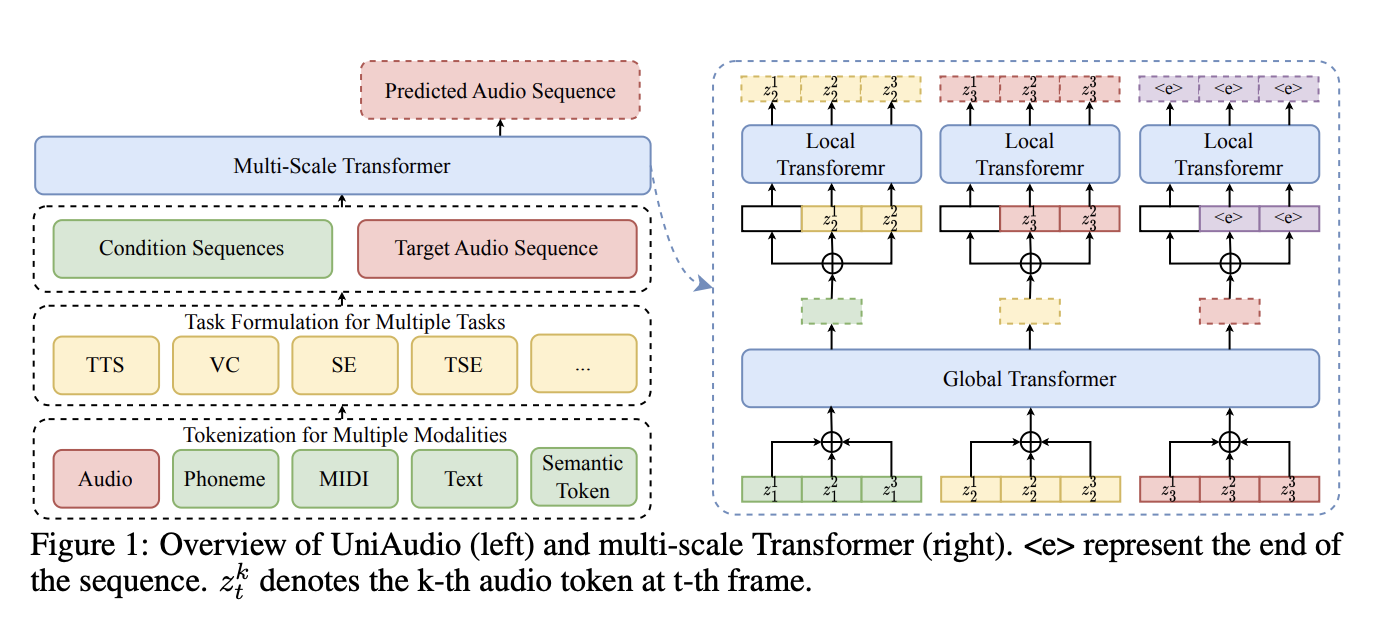
UniAudio 的核心目标,从名字就能看出来:
Universal Audio Generation
它想解决的不是某一个单独任务,而是一整类任务:
- TTS
- VC
- Singing voice synthesis
- Text-to-sound
- Text-to-music
- Audio editing
- Speech enhancement
- 以及其他音频生成 / 变换任务
UniAudio 最关键的地方,不是某个具体 backbone,而是它对任务的 抽象方式。
官方 README 把流程写得很直白,整个框架分成四步:
define your taskprepare datatokenize data and save it as .pthtraining and inference
这四步看起来很普通,但背后其实定义了 UniAudio 的方法论:
面对任何音频任务,先不要急着单独写一个模型,而是先把它规整成统一的数据格式。
# 2. UniAudio 的真正核心:任务先被定义成 “字段顺序”
UniAudio 仓库里最值得看的文件之一是 UniAudio/utils/task_definition.py 。
它在这里定义的不是网络结构,而是:
- 一个任务有哪些字段
- 每个字段属于什么类型
- 哪个字段是目标
- 在 encoder-decoder 或 decoder-only 场景下,这些字段应该怎么排列
README 里给的 TTS 例子,本质上就是:
1 | |
这个定义非常关键,因为它直接说明了:
phone_seq是条件prompt_seq是条件audio_seq是目标
随后 dataloader 会按照任务定义把这些字段拼起来,组成 单一序列,再交给同一个模型去处理。
这是 UniAudio 最 “基础模型化” 的地方。
它不是把逻辑写死成:
- “这是 TTS 模型”
- “这是 VC 模型”
- “这是歌声模型”
而是先统一抽象成:
一串离散 token,前面是条件,后面是待预测的目标。
# 3. UniAudio 是怎么把不同模态揉进一个词表的
另一个关键文件是 UniAudio/utils/dataloader.py 。
它主要做了几件事:
- 为不同数据类型构造 tokenizer
- 给不同类型分配各自的 token 区间
- 建立
type_bias - 把各种离散 token 映射进统一 vocabulary
比如:
audioaudio_promptphonetextsemantictext_t5sing_phonesing_midi
这些都可以共存在同一个统一词表里。
type_bias 这个设计尤其关键。可以粗略理解成:
同一个原始 token id,进入不同模态空间时,要加上不同偏置,避免彼此冲突。
所以 UniAudio 最终喂给模型的,不再是 “原始 phone token” 或者 “原始 codec token”,而是:
- 加过类型偏移后的统一 token
- 配上
<audio_start>、<text_start>这类 special token - 再按任务格式拼成一个长序列
因此,UniAudio 的本质不只是 “一个音频大模型”,而更像是:
一个统一 token 编排系统 + 一个统一序列建模器。
# 4. UniAudio 的模型抽象:把问题尽量改写成大语言模型问题
UniAudio 的 train.py 和 model.py 把这件事说明得更清楚。
训练时它做的是:
- 先通过
get_data_iterator_tokenizer_vocabulary(...)拿到 tokenized 数据 - 再构造
MegaByteModel - 最后统一做 next-token prediction /cross-entropy
这里的 MegaByteModel 很有意思。它不是普通 decoder-only LM,而更像一个 “全局 + 局部” 的层级解码器:
g_emb / g_layers / g_ln负责全局层l_emb / l_layers / l_ln负责局部层
背后的直觉是:
- 有些 token 的结构更接近 “帧级” 或 “块级” 组织;
- 有些 token 需要更细粒度的局部建模。
这也是 UniAudio 面对音频这种高频长序列还能勉强处理的原因:
它不是完全平铺,而是做了层级化 token 组织。
再加上 attention_mask(loss_mask, prefix_lm=True) 这种前缀条件掩码机制,UniAudio 就能支持:
- 前缀全部可见
- 目标段做因果预测
- padding 完全屏蔽
于是整套系统就成立了:
- 数据先被定义成统一格式
- 不同模态再被统一成离散 token
- token 被拼成一个长序列
- 一个大模型对目标段执行条件生成
这就是 UniAudio 的第一性原理。
# 5. 但 UniAudio 的问题也很明显:它太 “通用” 了
UniAudio 的强项是抽象足够统一,但代价也很清楚:
- 任务太多,整个系统更像研究框架,不像音乐产品栈;
- 音乐只是它支持的任务之一,而不是唯一中心;
- codec、文本条件、语义条件、任务定义都是通用抽象,并不是专门为歌曲设计;
- 对 “人声 + 伴奏 + 长歌结构 + 歌词控制” 这些音乐专属问题,优化不会那么极致。
换句话说,UniAudio 回答的是:
能不能用一个统一 token 框架去覆盖很多音频任务?
而 HeartMuLa 真正要回答的问题已经变成:
如果我只做音乐,而且重点是 lyrics-conditioned long-form music generation,那整个系统应该怎么重新收紧?
这就是从 UniAudio 到 HeartMuLa 的关键转折。
# 6. HeartMuLa 不是 “继续通用化”,而是 “音乐特化”
HeartMuLa 官方自己就把系统拆成了四块:
HeartMuLa:音乐语言模型HeartCodec:音乐 codecHeartTranscriptor:歌词转写HeartCLAP:音频 - 文本对齐
这说明它和 UniAudio 的路线已经明显不同。
UniAudio 更像:
- 一个通用音频建模框架
HeartMuLa /heartlib 更像:
- 一个面向音乐工作流的 专用技术栈
也就是说,HeartMuLa 并没有沿着 UniAudio 的 “任务大全” 姿态继续扩张,而是保留了最重要的那部分思想:
离散 token 统一建模
然后围绕 “音乐生成” 重新搭了一套更窄、更深、也更工程化的系统。
# 7. heartlib 的接口为什么看起来比 UniAudio 简单很多
如果直接看 heartlib 的使用入口,会感觉它比 UniAudio “收缩” 了很多。
最直接的入口是:
examples/run_music_generation.pysrc/heartlib/pipelines/music_generation.py
用户传进去的参数其实很少:
lyricstagsmodel_path- 一些采样参数,比如
topk、temperature、cfg_scale
和 UniAudio 相比,它少了很多:
- task json
- wav.scp
- phone.scp
- utt2spk
- 离线 tokenization pipeline
- task-specific formatter
这不是因为 HeartMuLa 更 “简陋”,恰恰相反,是因为它已经把任务空间大幅压缩了:
它默认做的,就是歌词 + tags 到音乐。
也就是说,UniAudio 里原本由任务定义系统显式处理的那一层,在 HeartMuLa 里已经被固化进 pipeline 本身。
# 8. heartlib 的生成入口,本质上是两段式
从 HeartMuLaGenPipeline 的代码来看,整条推理链非常清楚:
- 先定位模型路径
- 加载
HeartMuLa - 加载
HeartCodec - 加载
tokenizer.json - 加载
gen_config.json - 预处理
tags和lyrics - 让
HeartMuLa逐帧生成离散 music tokens - 再让
HeartCodec把 tokens 还原成波形
这和 UniAudio 很大的区别之一在于:
UniAudio 里的 tokenizer / dataloader / model / detokenizer 是统一框架中的通用流程;HeartMuLa 则把这条路径直接产品化成了固定 pipeline。
# 9. HeartMuLa 的输入组织方式:9 路并行 token
这里是我觉得最值得细看的地方。
在 music_generation.py 里,有两个常量很关键:
self._parallel_number = 8 + 1self._muq_dim = 512
这几乎已经把系统的 token 组织方式直接写出来了:
- 前
8路是音频 codebooks - 最后
1路是文本通道
也就是说,HeartMuLa 不是把文本和音频完全摊平成同一条 1D 序列,而是把每个时间步组织成一个二维小块:
1 | |
在 preprocess() 里,这个结构会被明确构造出来:
tokens的 shape 是[prompt_len, 9]- 最后一列放文本 token
- 前八列初始为空,后续由模型生成音频 token
这比 UniAudio 那种统一拼接更 “音乐专用”。
UniAudio 的逻辑更接近:
- 先把多模态信息顺序拼起来
HeartMuLa 的逻辑则更接近:
- 以 “时间帧” 为核心单位
- 在每个时间帧里并排组织多 codebook 音频 token 和文本条件
这是一个非常大的设计转向。
# 10. tags 和 lyrics 在 HeartMuLa 里是怎么进模型的
预处理阶段大致会做这些事:
# tags
- 如果
tags是文件路径,就先读文件 - 转成小写
- 自动补上
<tag>和</tag> - 用文本 tokenizer 编码
- 保证有
text_bos_id和text_eos_id
# lyrics
- 同样支持路径或字符串输入
- 转成小写
- 文本 tokenizer 编码
- 同样补 BOS / EOS
然后它们会被拼成一个文本前缀,塞进 tokens[:, -1] ,也就是最后一列文本轨道。
从建模角度看,这相当于说:
tags负责全局风格条件lyrics负责长程语义内容和歌词对齐- 两者共享同一个文本 token 空间
这一层其实仍然能看到 UniAudio 的影子:
条件先被 token 化,再进入统一序列建模。
只是到了 HeartMuLa,这件事已经不再需要 UniAudio 那种通用 task formatter,而是直接被写死成 “tags + lyrics” 的音乐生成输入协议。
# 11. 还有一个预留口:连续条件段
在 preprocess() 里还有一块很有意思:
muq_embedmuq_idx
当前实现里, ref_audio 还没有真正开放,默认是一个全零向量;但从代码接口看得很清楚,HeartMuLa 已经给 “连续向量条件” 留出了位置。
在 HeartMuLa.generate_frame() 里,这个连续向量会经过:
self.muq_linear
然后被写入某个指定时间步 starts 。
这意味着它不仅支持离散文本 token 条件,还预留了:
把连续的音乐语义 embedding 插进生成过程
这和 UniAudio 的 continuous_segments 思想是同源的,只不过 HeartMuLa 把它做成了一个更明确、也更偏音乐场景的接口。
# 12. HeartMuLa 的模型结构:不是单个 LM,而是 backbone + frame decoder
如果去看 src/heartlib/heartmula/modeling_heartmula.py ,会发现 HeartMuLa 的结构设计非常有针对性。
它不是直接拿一个 LLaMA 输出所有 token,而是拆成两段:
backbonedecoder
并且这两段都来自 llama3_2 family 的变体:
llama-3Bllama-300Mllama-7Bllama-400M
官方默认配置里:
backbone_flavor = "llama-3B"decoder_flavor = "llama-300M"
这个搭配很能说明问题。
我的理解是:
- 大 backbone 负责跨时间的长程建模
- 小 decoder 负责在单个时间帧内,把剩余 codebooks 补全
也就是说,HeartMuLa 把生成问题拆成了两个粒度:
- 先决定当前 frame 的 “主 token / 主语义”
- 再把这一帧剩余的 codebooks 补齐
这和 UniAudio 的 MegaByte 分层思想非常接近,只是写法更直接,也更贴合音乐 codec 的多 codebook 现实。
# 13. HeartMuLa.generate_frame () 到底做了什么
这是整个 heartlib 里最关键的函数之一。
它的逻辑可以拆成下面几步:
# 第一步:嵌入当前输入
_embed_tokens() 会把当前 token block 变成 embedding:
- 文本列走
text_embeddings - 音频 codebooks 走
audio_embeddings
而且音频 embedding 并不是简单查表,它会按 codebook 编号加偏移:
1 | |
也就是说:
- 第 0 个 codebook 的 token 空间
- 第 1 个 codebook 的 token 空间
- …
- 第 7 个 codebook 的 token 空间
都会被映射到同一个大 embedding 表里,但彼此不会冲突。
这和 UniAudio 里的 type_bias 本质相同,只不过这里的 bias 不再是 “模态级”,而是更细的 codebook 级。
# 第二步:把这一帧所有模态 merge 成一个 backbone 输入
代码里有一句特别关键:
1 | |
这说明在进入 backbone 之前,HeartMuLa 会把:
- 8 个 audio codebook embeddings
- 1 个 text embedding
先在帧内做聚合。
这一步的含义是:
- backbone 看到的是 每个时间步的综合表示
- 而不是 9 条平行序列分别做自注意力
换句话说,HeartMuLa 的 backbone 更像是在看 “帧级音乐状态”,而不是细粒度 token 网格。
# 第三步:用 backbone 预测当前帧的第一个音频 codebook
backbone 输出最后一个时间步的隐藏状态 last_h 之后,会先经过:
codebook0_head
拿到第一个 codebook 的 logits。
这个步骤很像 “先决定这一帧的主符号”。
# 第四步:再用小 decoder 依次补完其余 codebooks
拿到 c0_sample 之后,会先把它 embed 成 c0_embed ,再和 last_h 一起送进小 decoder。
然后循环预测:
- codebook 1
- codebook 2
- …
- codebook 7
所以,整个单帧生成过程其实就是:
- backbone 决定 frame 级主语义
- decoder 在这一帧内部自回归地补完细节 codebooks
这也是它和 UniAudio 最核心的结构继承关系:
- 都不是 “纯平铺 token LM”
- 都有明显的层级生成思想
但 HeartMuLa 把层级从 UniAudio 的 “global/local token block” 改写成了更适合音乐 codec 的:
- 跨帧 backbone
- 帧内 codebook decoder
# 14. HeartMuLa 的 CFG 是怎么做的
HeartMuLa 还内置了 classifier-free guidance 。
这一点在 generate_frame() 里能直接看到:
- 如果
cfg_scale > 1.0 - batch 会复制成 cond /uncond 两支
- 文本条件在 uncond 分支里会被替换成
unconditional_text_embedding - 最后通过
1 | |
做 guidance
这一步也很关键,因为它说明 HeartMuLa 已经不只是传统 LM 采样,而是在借用 diffusion /multimodal generation 里非常成熟的 guidance 思想,去增强条件控制。
这也是它比 UniAudio 更 “音乐生成专用” 的地方:
UniAudio 的重点是统一框架,HeartMuLa 的重点已经变成了 控制质量和条件响应性。
# 15. 整首歌是怎么一步一步生成出来的
在 HeartMuLaGenPipeline._forward() 里,整首歌的生成主循环写得非常直白:
# 初始步
- 先把
tags + lyrics前缀送进模型 - 调一次
generate_frame() - 得到第一个音频 frame 的 8 个 codebook token
# 之后的每一步
每一步都做:
- 把上一步生成的音频 token pad 成
[1, 9]结构 - 前 8 列放音频 token
- 最后一列文本置空
- 再调一次
generate_frame()
循环上限是:
1 | |
这个式子非常关键,因为它说明 HeartMuLa 的时间步长是:
- 每帧 80 ms
所以:
120000 ms大约是1500帧240000 ms大约是3000帧
这和歌曲的长时长生成是匹配的。
当任一 codebook 里出现 audio_eos_id 时,生成就会停止。
最后,所有 frame 会被堆成:
[num_codebooks, time]
也就是一条完整的离散音乐 token 序列。
# 16. 这一步其实就是 “音乐版 language model”
如果把 HeartMuLa 的生成过程再抽象一下,它做的就是:
- 文本条件提供歌曲语义与风格
- 模型沿时间帧自回归
- 每个时间帧内部再补全多 codebook token
所以它仍然是语言模型思路,只不过这里的 “语言” 已经不再是单一文本 token,而是:
- 时间上的 frame
- 帧内的多 codebook 并行结构
这就是为什么我会说 HeartMuLa 是从 UniAudio 这条线自然长出来的。
它继承的不是某几个具体脚本,而是 “把音频生成转写成统一离散建模” 的世界观。
# 17. 生成的 token 最后怎么变成声音:HeartCodec
HeartMuLa 只负责产出 token,并不直接输出 waveform。
真正把 token 还原成声音的是 HeartCodec 。
这部分逻辑在:
src/heartlib/heartcodec/modeling_heartcodec.py
里面最核心的接口是:
HeartCodec.detokenize(codes, ...)
从配置上就能看出来,HeartCodec 并不是一个简单解码器,而是由两部分组成:
FlowMatchingScalarModel
直觉上可以理解成:
- 先根据离散 codes 生成连续 latent
- 再把 latent decode 成最终波形
# 具体过程
detokenize() 里会先:
- 把 code 序列搬到 device 上
- 初始化一个随机 latent
first_latent - 按滑窗切分 codes
- 每段调用
flow_matching.inference_codes(...)
也就是说,离散 codes 并不是直接送进一个简单反量化器,而是要先经过 flow matching 做连续 latent 重建。
然后,得到的 latent 会再经过:
self.scalar_model.decode(...)
还原成最终音频。
这一步其实很像在明确分工:
HeartMuLa负责高层音乐 token 建模HeartCodec负责高保真音频重建
这和 UniAudio 里 “统一框架中同时包含 codec 和 generative LM” 的思路并不矛盾,只是 HeartMuLa 把两者边界切得更清楚。
# 18. HeartCodec 为什么重要
如果没有 HeartCodec,HeartMuLa 只是一套 token generator。
而 HeartCodec 的重要性在于,它直接决定了:
- 同样长度的 token 序列能承载多少音乐信息
- 离散 token 到高保真音频的损失有多大
- 系统最终听感能不能接近产品级
HeartMuLa README 里也明确把这点讲出来了:
HeartMuLa是语言模型HeartCodec是高保真 music codec
这说明它并没有把 codec 当成辅助工具,而是把它视为音乐 foundation model 家族的一部分。
这也是它和早期 UniAudio 最大的实用差异之一:
- UniAudio 更像统一研究框架
- HeartMuLa 更像 把 codec 也一起产品化
# 19. 所以,从 UniAudio 到 HeartMuLa,真正继承了什么
我觉得这条路径真正继承了四件事。
# 第一,离散化优先
两者都相信:
- 原始波形太长,直接建模成本太高
- 应该先用 codec 把音频变成离散 token
# 第二,统一序列建模
两者都相信:
- 文字、音频条件、语义条件,本质上都可以变成 token 或 embedding
- 再通过统一序列模型完成生成
# 第三,条件和目标的边界可以程序化定义
在 UniAudio 里,这体现在 task definition。
在 HeartMuLa 里,这体现在固定的:
- tags
- lyrics
- audio frames
输入协议。
# 第四,层级建模比平铺建模更适合音频
UniAudio 用的是 MegaByte 风格的 global/local。
HeartMuLa 用的是:
- 跨帧 backbone
- 帧内 decoder
它们形式不同,但本质都在做同一件事:
把长音频生成拆成不同粒度去建模。
# 20. 那 HeartMuLa 又抛弃了 UniAudio 的什么
同样重要的是,它也放弃了不少 UniAudio 的东西。
# 放弃了 “万能任务框架”
HeartMuLa 不再试图让一个训练框架同时优雅覆盖几十种任务。
# 放弃了 “先抽象到极致再说”
它更像是先承认:
- 音乐就是一个特殊任务
- 歌词、风格、人声、伴奏、长时长结构都很特殊
所以值得单独设计一套专用系统。
# 放弃了 “研究框架优先”
HeartMuLa /heartlib 明显更偏向:
- 在线推理
- checkpoint 组织
- pipeline 固化
- 本地部署体验
也就是更接近 “库” 和 “产品” 的形态。
# 21. 我对这条路径的最终判断
如果把 UniAudio 和 HeartMuLa 看成一条连续技术路线,我会这样理解:
UniAudio 解决的是:
如何把音频世界里的不同任务统一成一个序列建模问题?
HeartMuLa 解决的是:
在这个统一思想成立之后,怎样把它收缩成一个真正能打的音乐系统?
所以:
- UniAudio 提供的是范式
- HeartMuLa 提供的是面向音乐的专门化落地
从代码层面,你能很清楚地看到这条继承关系:
-
UniAudio 的
task definition / tokenizer / type bias / unified sequence
变成了 HeartMuLa 的tags + lyrics + frame-wise multi-codebook tokens -
UniAudio 的统一 LM 思想
变成了 HeartMuLa 的LLaMA backbone + frame decoder -
UniAudio 的 codec-first worldview
变成了 HeartMuLa 的HeartCodec + HeartMuLa双模块系统
如果再往后推一步,我会认为这条路线真正的下一站,很可能是:
- 更强的 reference audio conditioning
- 更细粒度的 segment planning
- 更高效的 streaming /acceleration
- 更完整的音乐编辑工作流
因为 HeartMuLa 当前公开代码里,其实已经把这些扩展位预留出来了。
# 参考链接
- UniAudio GitHub: https://github.com/yangdongchao/UniAudio
- UniAudio Paper: https://arxiv.org/abs/2310.00704
- HeartMuLa / heartlib GitHub: https://github.com/HeartMuLa/heartlib
- HeartMuLa Paper: https://arxiv.org/abs/2601.10547
- YuE GitHub: https://github.com/multimodal-art-projection/YuE
- YuE Paper: https://arxiv.org/abs/2503.08638
- DiffRhythm GitHub: https://github.com/ASLP-lab/DiffRhythm
- DiffRhythm Paper: https://arxiv.org/abs/2503.01183
- ACE-Step GitHub: https://github.com/ace-step/ACE-Step
- ACE-Step Paper: https://arxiv.org/abs/2506.00045
- ACE-Step 1.5 Paper: https://arxiv.org/abs/2602.00744
- LeVo / SongGeneration GitHub: https://github.com/tencent-ailab/SongGeneration
- LeVo Paper: https://arxiv.org/abs/2506.07520
- Muse GitHub: https://github.com/yuhui1038/Muse
- Muse Paper: https://arxiv.org/abs/2601.03973